03_RNA_quality_control
Nils Eling/Daniel Schulz/Tobias Hoch
2020-07-28
Last updated: 2022-02-22
Checks: 7 0
Knit directory: MelanomaIMC/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200728) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version d246c15. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rproj.user/
Ignored: Table_S4.csv
Ignored: code/.DS_Store
Ignored: code/._.DS_Store
Ignored: data/.DS_Store
Ignored: data/._.DS_Store
Ignored: data/data_for_analysis/
Ignored: data/full_data/
Unstaged changes:
Modified: .gitignore
Modified: analysis/Supp-Figure_10.rmd
Modified: analysis/_site.yml
Deleted: analysis/license.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/03_RNA_quality_control.rmd) and HTML (docs/03_RNA_quality_control.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 5418dcd | toobiwankenobi | 2022-02-22 | add remaining pngs and new .htmls |
| html | 73aa800 | toobiwankenobi | 2022-02-22 | add .html for static website |
| html | 4109ff1 | toobiwankenobi | 2021-07-07 | delete html files and adapt gitignore |
| html | 3203891 | toobiwankenobi | 2021-02-19 | change celltype names |
| Rmd | ee1595d | toobiwankenobi | 2021-02-12 | clean repo and adapt files |
| html | ee1595d | toobiwankenobi | 2021-02-12 | clean repo and adapt files |
| Rmd | 2e443a5 | toobiwankenobi | 2021-02-09 | remove files that are not needed |
| html | 3f5af3f | toobiwankenobi | 2021-02-09 | add .html files |
| Rmd | f9bb33a | toobiwankenobi | 2021-02-04 | new Figure 5 and minor changes in figure order |
| Rmd | 2ac1833 | toobiwankenobi | 2021-01-08 | changes to Figures |
| Rmd | d8819f2 | toobiwankenobi | 2020-10-08 | read new data (nuclei expansion) and adapt scripts |
| Rmd | fb0f7cb | SchulzDan | 2020-08-24 | more paths adapted |
| Rmd | 2c11d5c | toobiwankenobi | 2020-08-05 | add new scripts |
| Rmd | e9cc8b2 | toobiwankenobi | 2020-07-30 | rename files |
Preparations
Load libraries
sapply(list.files("code/helper_functions", full.names = TRUE), source) code/helper_functions/calculateSummary.R
value ?
visible FALSE
code/helper_functions/censor_dat.R
value ?
visible FALSE
code/helper_functions/detect_mRNA_expression.R
value ?
visible FALSE
code/helper_functions/DistanceToClusterCenter.R
value ?
visible FALSE
code/helper_functions/findMilieu.R code/helper_functions/findPatch.R
value ? ?
visible FALSE FALSE
code/helper_functions/getInfoFromString.R
value ?
visible FALSE
code/helper_functions/getSpotnumber.R
value ?
visible FALSE
code/helper_functions/plotCellCounts.R
value ?
visible FALSE
code/helper_functions/plotCellFractions.R
value ?
visible FALSE
code/helper_functions/plotDist.R code/helper_functions/read_Data.R
value ? ?
visible FALSE FALSE
code/helper_functions/scatter_function.R
value ?
visible FALSE
code/helper_functions/sceChecks.R
value ?
visible FALSE
code/helper_functions/validityChecks.R
value ?
visible FALSE library(SingleCellExperiment)
library(dplyr)
library(ggplot2)
library(scater)
library(CATALYST)
library(reshape2)
library(viridis)
library(ggridges)
library(cowplot)
library(BiocParallel)
library(dittoSeq)Load the single cell experiment object and the image metadata
sce <- readRDS(file = "data/data_for_analysis/sce_RNA.rds")Assay
Add different assays
assay(sce, "scaled_counts") <- t(scale(t(assay(sce, "counts"))))
assay(sce, "scaled_asinh") <- t(scale(t(assay(sce, "asinh"))))General Plots
Plot Cell Counts for every Image
# this function takes all the column metadata from the sce and plots parts thereof
plotCellCounts(sce, colour_by = "Location", split_by = "ImageNumber", imageID = "ImageNumber")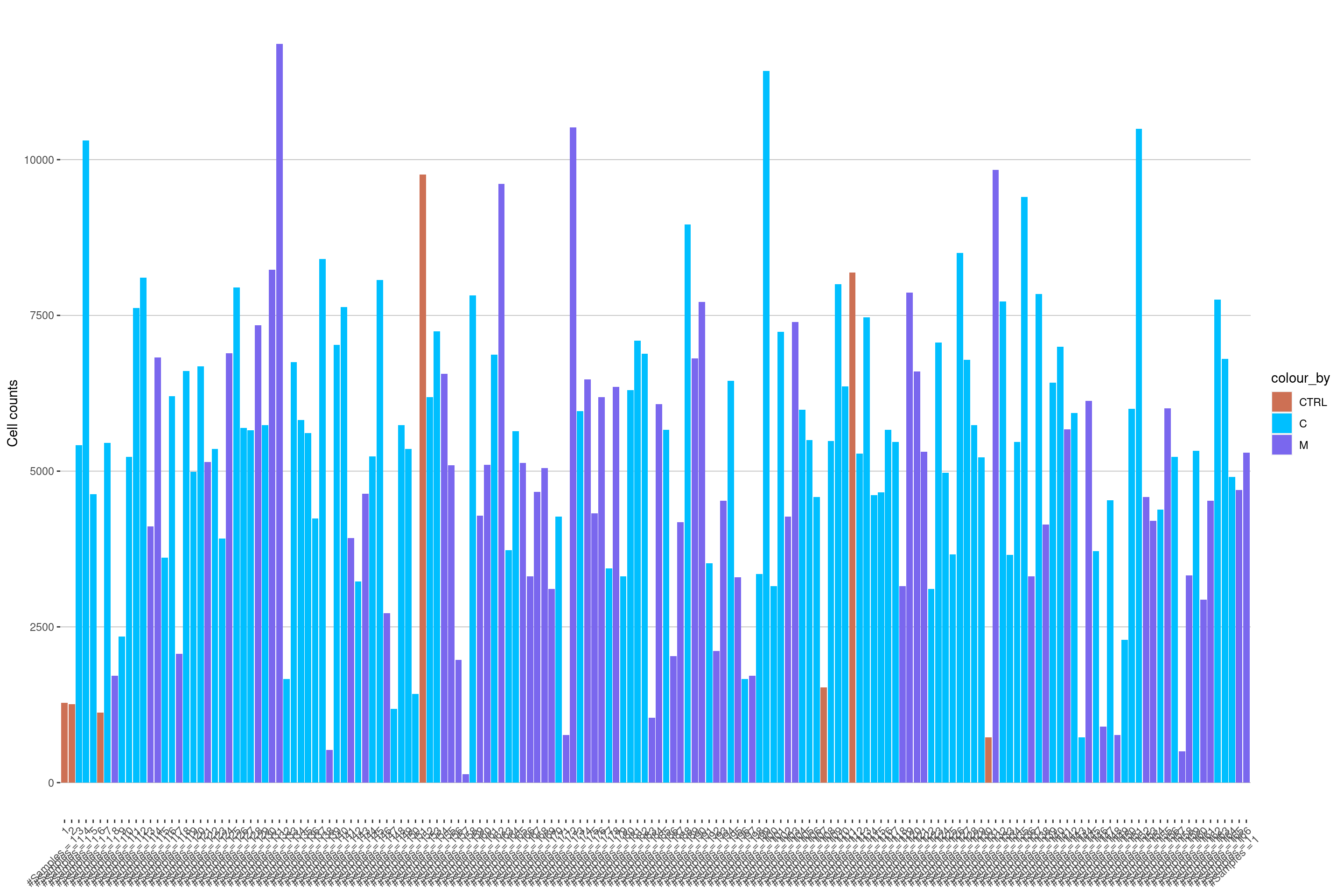
| Version | Author | Date |
|---|---|---|
| 1dc2e93 | toobiwankenobi | 2022-02-22 |
Image 57 has only a few cells and should probably be excluded.
will be flagged below
cur_sce <- data.frame(colData(sce))
# show images with less than 500 cells
cur_sce %>%
group_by(ImageNumber) %>%
summarise(n=n()) %>%
filter(n<500)# A tibble: 1 × 2
ImageNumber n
<int> <int>
1 57 136Flag image in sce object for future exclusion
# define vector for each single cell whether to keep (TRUE) or not (FALSE)
includeImage <- colData(sce)$ImageNumber != 57
sce$includeImage <- includeImageMean intensity of markers per image
# we use a function from Nils. This function makes use of the aggregate function to calculate the mean for each channel over all specified groups
mean_sce <- calculateSummary(sce, split_by = c("ImageNumber", "BlockID", "Location","Mutation","Cancer_Stage", "Status_at_3m","E_I_D","Adjuvant"), exprs_values = "counts")Transform data
assay(mean_sce, "asinh") <- asinh(assay(mean_sce, "meanCounts"))
assay(mean_sce, "asinh_scaled") <- t(scale(t(asinh(assay(mean_sce, "meanCounts")))))Plot the mean data
# first we define a vector of markers that we want to plot
plot_targets <- rownames(sce)
plot_targets <- plot_targets[! plot_targets %in% c("DNA1","DNA2","HistoneH3")]
# now we plot the heatmap
plotHeatmap(mean_sce,features = plot_targets ,exprs_values = "asinh",colour_columns_by = "ImageNumber",color = viridis(100))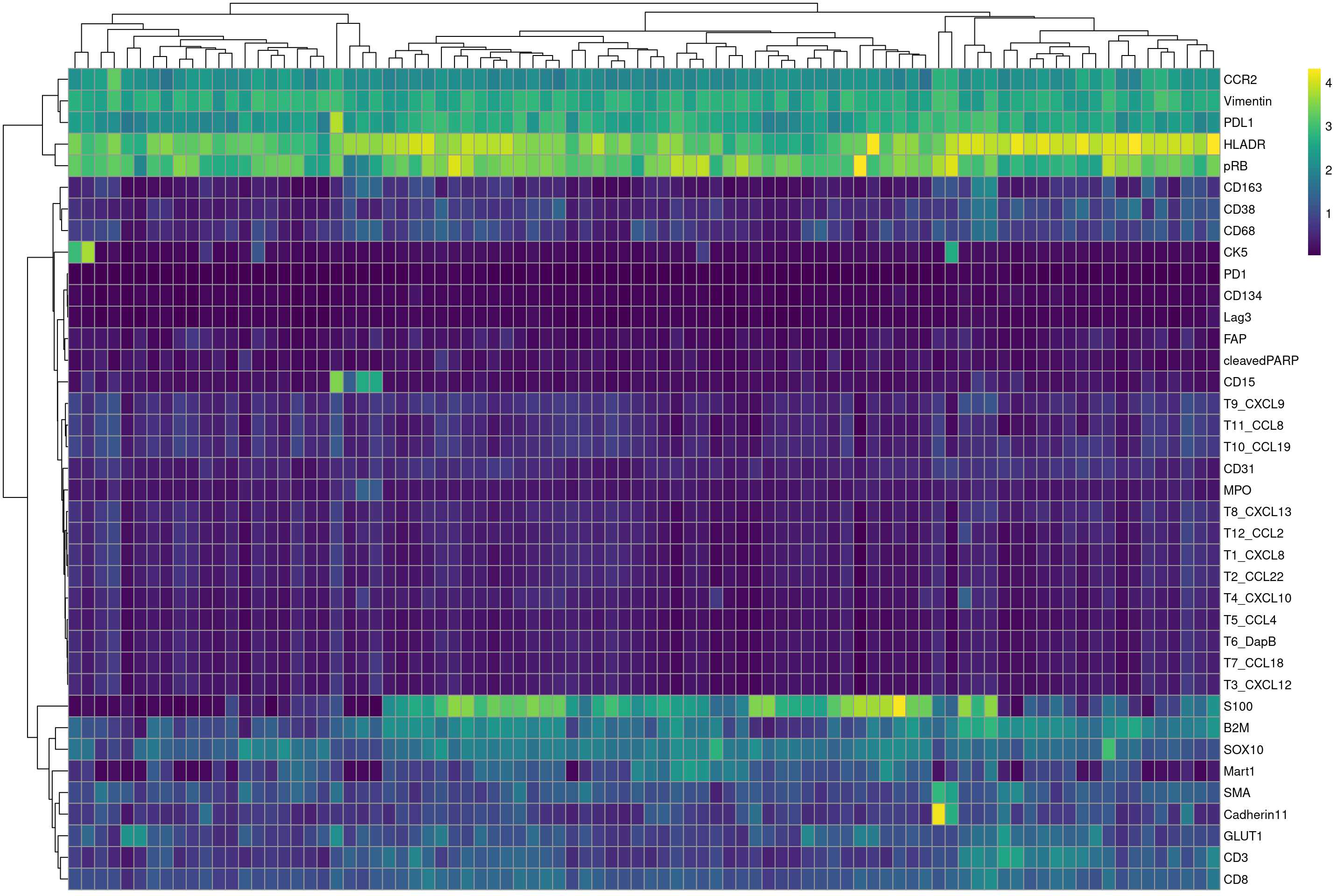
| Version | Author | Date |
|---|---|---|
| 1dc2e93 | toobiwankenobi | 2022-02-22 |
Plot the scaled data
# now we plot the scaled heatmap
plotHeatmap(mean_sce,features = plot_targets, exprs_values = "asinh_scaled", colour_columns_by = c("ImageNumber"), zlim = c(-3,3),
color = colorRampPalette(c("dark blue", "white", "dark red"))(100))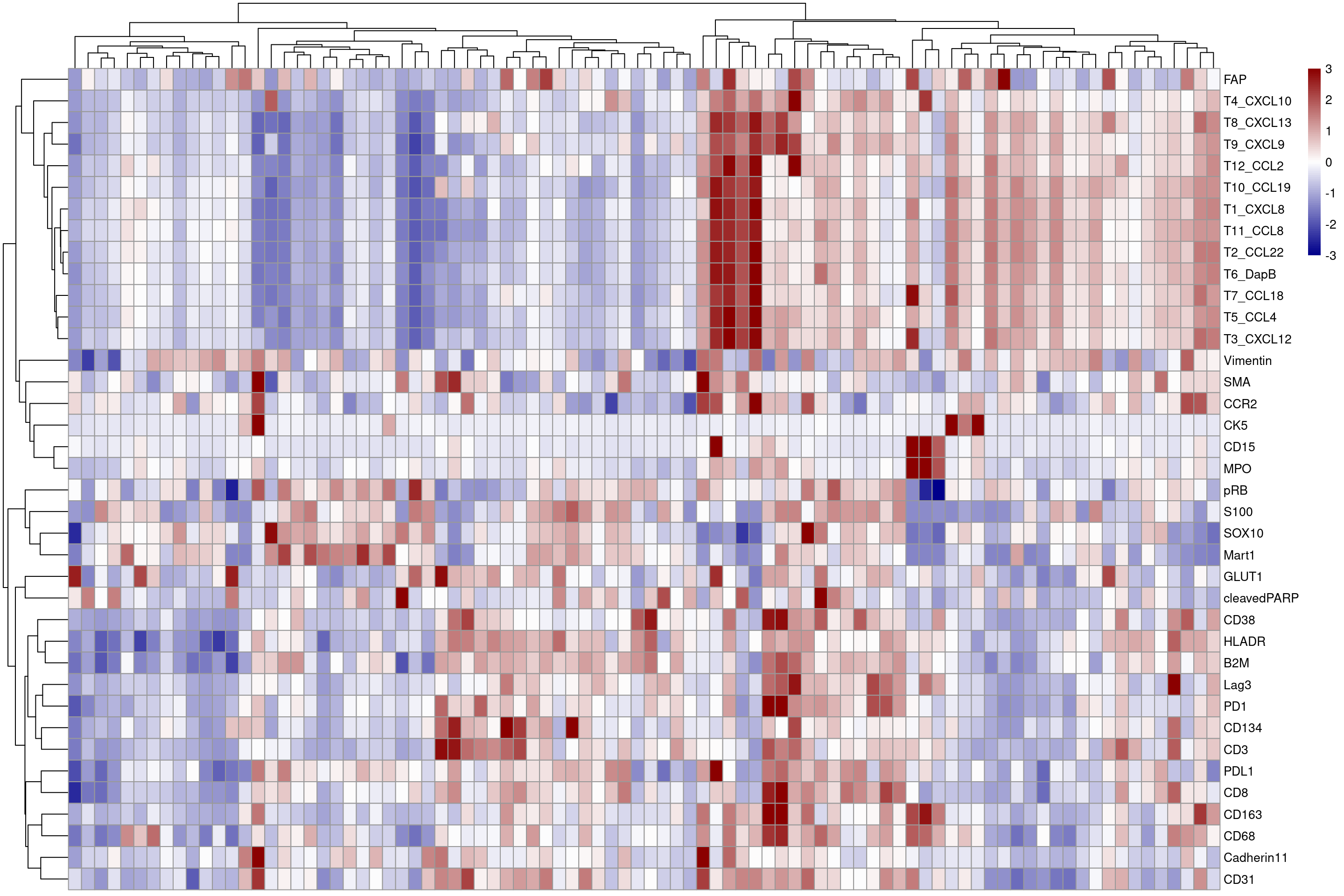
| Version | Author | Date |
|---|---|---|
| 1dc2e93 | toobiwankenobi | 2022-02-22 |
Cell level quality control
here we plot the marker intensity distributions for all images. since we have too many images we make groups of 10.
y <- c(rep(1:10,16),rep(11,7))
# add the group information to the sce object
sce$groups <- y[colData(sce)$ImageNumber]
# now we use the function written by Nils
plotDist(sce, plot_type = "ridges",
colour_by = "groups", split_by = "rows",
exprs_values = "asinh") +
theme_minimal(base_size = 15)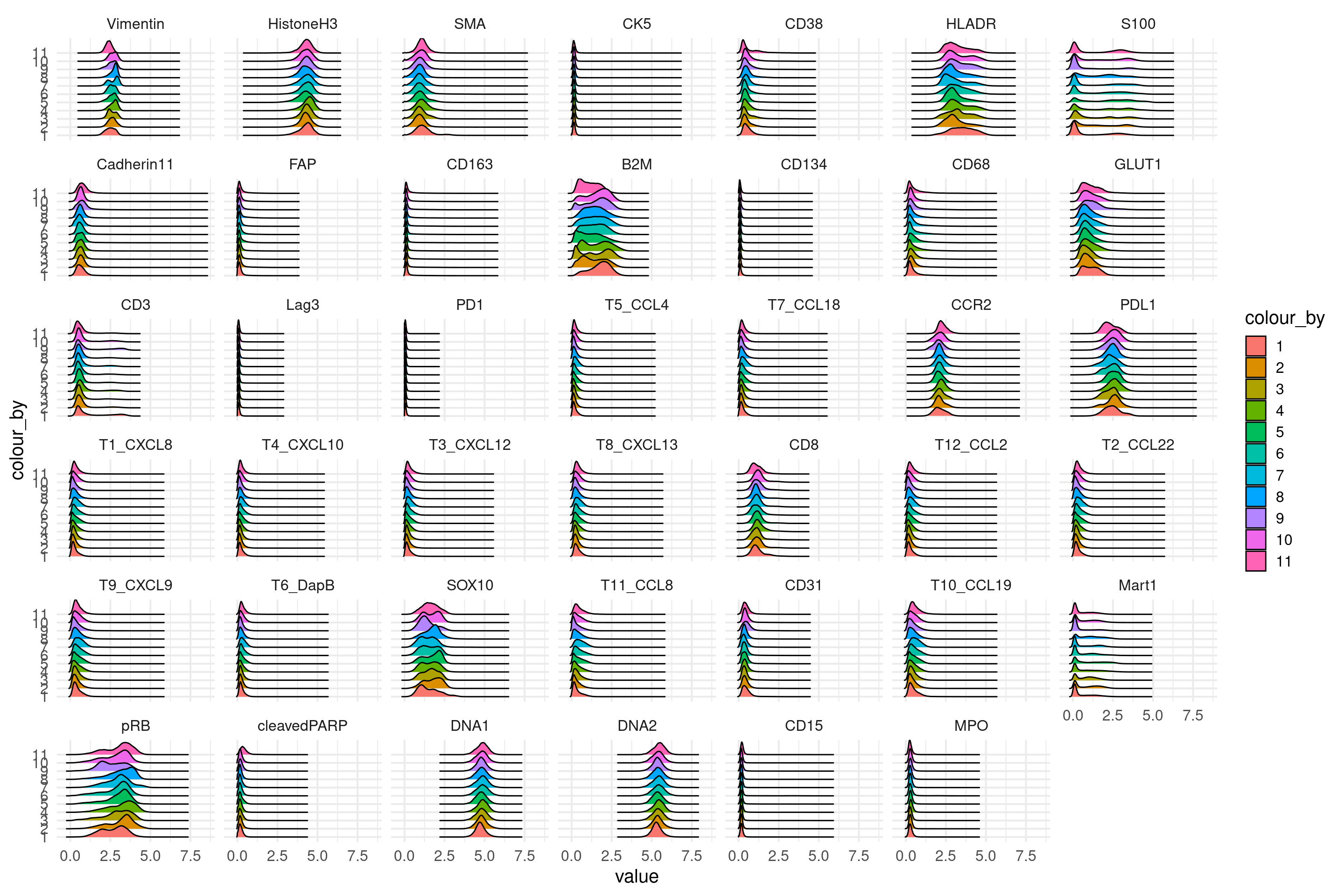
| Version | Author | Date |
|---|---|---|
| 1dc2e93 | toobiwankenobi | 2022-02-22 |
# the distributions look very even across images indicating that we have no major batch effects.Define markers which had poor staining
By visual inspection, we defined bad markers
rowData(sce)$good_marker <- ! grepl("DNA|Histone|Vimentin|PD1|PDL1|CCR2|CK5",rownames(sce))
# good_marker without RNA channels
rowData(sce)$noRNA_marker <- ! grepl("DNA|Histone|Vimentin|PD1|PDL1|CCR2|CK5|CXCL|CCL|DapB",rownames(sce))Calculate UMAP
set.seed(12345)
# UMAP
start = Sys.time()
sce <- runUMAP(sce, exprs_values = "scaled_counts",
subset_row = rowData(sce)$good_marker)
end = Sys.time()
print(end-start)Time difference of 8.173838 minsSubset SCE for UMAP visualization
cur_sce <- sce[, colnames(sce) %in% sample(sce$cellID, round(length(sce$cellID)*0.05))]
cur_sce$ImageNumber <- as.character(cur_sce$ImageNumber)Visualize features on and UMAP
Next, we will visualize different quality features on these representations.
UMAP
# Select plots in list
p.list <- list()
#
p.list$ImageNumber <- dittoDimPlot(cur_sce, var = "ImageNumber", reduction.use = "UMAP", size = 0.5, legend.show = FALSE)
p.list$Mutation <- dittoDimPlot(cur_sce, var = "Mutation", reduction.use = "UMAP", size = 0.5)
p.list$Cancer_Stage <- dittoDimPlot(cur_sce, var = "Cancer_Stage", reduction.use = "UMAP", size = 0.5)
p.list$relapse <- dittoDimPlot(cur_sce, var = "relapse", reduction.use = "UMAP", size = 0.5)
p.list$Location <- dittoDimPlot(cur_sce, var = "Location", reduction.use = "UMAP", size = 0.5)
p.list$TissueType <- dittoDimPlot(cur_sce, var = "TissueType", reduction.use = "UMAP", size = 0.5)
p.list$MM_location_simplified <- dittoDimPlot(cur_sce, var = "MM_location_simplified", reduction.use = "UMAP", size = 0.5)
p.list$treatment_group_before_surgery <- dittoDimPlot(cur_sce, var = "treatment_group_before_surgery", reduction.use = "UMAP", size = 0.5)
plot_grid(plotlist = p.list, ncol = 4, rel_widths = c(1.5, 1, 1, 1))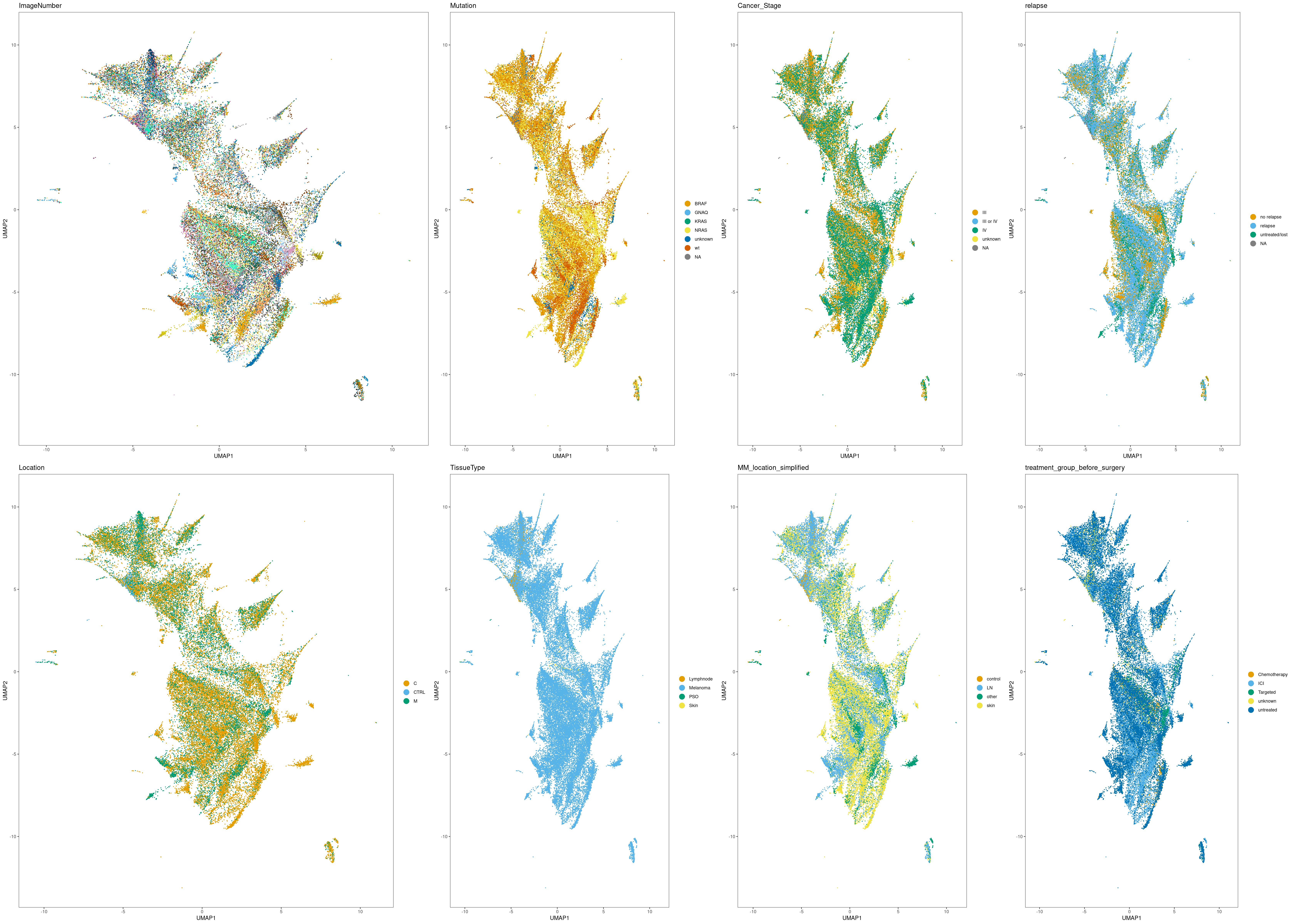
| Version | Author | Date |
|---|---|---|
| 1dc2e93 | toobiwankenobi | 2022-02-22 |
Save data
Save updated SCE object
saveRDS(sce, file = "data/data_for_analysis/sce_RNA.rds")
sessionInfo()R version 4.1.2 (2021-11-01)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.04.3 LTS
Matrix products: default
BLAS/LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.8.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] dittoSeq_1.6.0 BiocParallel_1.28.3
[3] cowplot_1.1.1 ggridges_0.5.3
[5] viridis_0.6.2 viridisLite_0.4.0
[7] reshape2_1.4.4 CATALYST_1.18.1
[9] scater_1.22.0 scuttle_1.4.0
[11] ggplot2_3.3.5 SingleCellExperiment_1.16.0
[13] SummarizedExperiment_1.24.0 Biobase_2.54.0
[15] GenomicRanges_1.46.1 GenomeInfoDb_1.30.1
[17] IRanges_2.28.0 S4Vectors_0.32.3
[19] BiocGenerics_0.40.0 MatrixGenerics_1.6.0
[21] matrixStats_0.61.0 dplyr_1.0.7
[23] workflowr_1.7.0
loaded via a namespace (and not attached):
[1] utf8_1.2.2 tidyselect_1.1.1
[3] grid_4.1.2 Rtsne_0.15
[5] aws.signature_0.6.0 flowCore_2.6.0
[7] munsell_0.5.0 ScaledMatrix_1.2.0
[9] codetools_0.2-18 withr_2.4.3
[11] colorspace_2.0-2 highr_0.9
[13] knitr_1.37 rstudioapi_0.13
[15] ggsignif_0.6.3 labeling_0.4.2
[17] git2r_0.29.0 GenomeInfoDbData_1.2.7
[19] polyclip_1.10-0 farver_2.1.0
[21] pheatmap_1.0.12 flowWorkspace_4.6.0
[23] rprojroot_2.0.2 vctrs_0.3.8
[25] generics_0.1.2 TH.data_1.1-0
[27] xfun_0.29 R6_2.5.1
[29] doParallel_1.0.16 ggbeeswarm_0.6.0
[31] clue_0.3-60 rsvd_1.0.5
[33] bitops_1.0-7 DelayedArray_0.20.0
[35] assertthat_0.2.1 promises_1.2.0.1
[37] scales_1.1.1 multcomp_1.4-18
[39] beeswarm_0.4.0 gtable_0.3.0
[41] beachmat_2.10.0 processx_3.5.2
[43] RProtoBufLib_2.6.0 sandwich_3.0-1
[45] rlang_1.0.0 GlobalOptions_0.1.2
[47] splines_4.1.2 rstatix_0.7.0
[49] hexbin_1.28.2 broom_0.7.12
[51] yaml_2.2.2 abind_1.4-5
[53] backports_1.4.1 httpuv_1.6.5
[55] RBGL_1.70.0 tools_4.1.2
[57] ellipsis_0.3.2 jquerylib_0.1.4
[59] RColorBrewer_1.1-2 Rcpp_1.0.8
[61] plyr_1.8.6 base64enc_0.1-3
[63] sparseMatrixStats_1.6.0 zlibbioc_1.40.0
[65] purrr_0.3.4 RCurl_1.98-1.5
[67] ps_1.6.0 FlowSOM_2.2.0
[69] ggpubr_0.4.0 GetoptLong_1.0.5
[71] zoo_1.8-9 ggrepel_0.9.1
[73] cluster_2.1.2 colorRamps_2.3
[75] fs_1.5.2 magrittr_2.0.2
[77] RSpectra_0.16-0 ncdfFlow_2.40.0
[79] data.table_1.14.2 scattermore_0.7
[81] circlize_0.4.13 mvtnorm_1.1-3
[83] whisker_0.4 ggnewscale_0.4.5
[85] evaluate_0.14 XML_3.99-0.8
[87] jpeg_0.1-9 gridExtra_2.3
[89] shape_1.4.6 ggcyto_1.22.0
[91] compiler_4.1.2 tibble_3.1.6
[93] crayon_1.4.2 ggpointdensity_0.1.0
[95] htmltools_0.5.2 later_1.3.0
[97] tidyr_1.2.0 RcppParallel_5.1.5
[99] aws.s3_0.3.21 DBI_1.1.2
[101] tweenr_1.0.2 ComplexHeatmap_2.10.0
[103] MASS_7.3-55 Matrix_1.4-0
[105] car_3.0-12 cli_3.1.1
[107] parallel_4.1.2 igraph_1.2.11
[109] pkgconfig_2.0.3 getPass_0.2-2
[111] xml2_1.3.3 foreach_1.5.2
[113] vipor_0.4.5 bslib_0.3.1
[115] XVector_0.34.0 drc_3.0-1
[117] stringr_1.4.0 callr_3.7.0
[119] digest_0.6.29 RcppAnnoy_0.0.19
[121] ConsensusClusterPlus_1.58.0 graph_1.72.0
[123] rmarkdown_2.11 uwot_0.1.11
[125] DelayedMatrixStats_1.16.0 curl_4.3.2
[127] gtools_3.9.2 rjson_0.2.21
[129] lifecycle_1.0.1 jsonlite_1.7.3
[131] carData_3.0-5 BiocNeighbors_1.12.0
[133] fansi_1.0.2 pillar_1.7.0
[135] lattice_0.20-45 plotrix_3.8-2
[137] fastmap_1.1.0 httr_1.4.2
[139] survival_3.2-13 glue_1.6.1
[141] png_0.1-7 iterators_1.0.13
[143] Rgraphviz_2.38.0 nnls_1.4
[145] ggforce_0.3.3 stringi_1.7.6
[147] sass_0.4.0 BiocSingular_1.10.0
[149] CytoML_2.6.0 latticeExtra_0.6-29
[151] cytolib_2.6.1 irlba_2.3.5